
구글, AI 추론 전쟁 판도를 바꿀 비밀 병기 '아이언우드'! (10배 빠른 자체 칩)
안녕하세요! 인공지능(AI) 경쟁이 모델 개발을 넘어 실제 서비스 적용, 즉 '추론(Inference)' 단계로 넘어가면서, 누가 더 빠르고 효율적으로 AI를 구동하느냐가 핵심 승부처로 떠오르고 있습니다. 이런 흐름 속에서 구글이 자체 개발한 차세대 AI 가속기 칩 '아이언우드(Ironwood)'를 선보이며 기술 패권 경쟁에 강력한 출사표를 던졌습니다!
이전 세대 대비 추론 속도를 무려 10배 향상시켰다는 아이언우드. 단순한 성능 개선을 넘어, AI 추론에 특화된 설계를 통해 비용 효율성까지 극대화했다고 하는데요. 과연 아이언우드는 어떤 괴물 같은 성능을 숨기고 있을까요? 왜 구글은 자체 칩 개발에 열을 올리는 걸까요? 그리고 이 새로운 칩이 AI 산업과 우리의 미래에 어떤 영향을 미치게 될까요?
오늘은 구글의 최신 TPU, 아이언우드의 모든 것을 공식 발표 내용과 학술적 배경을 바탕으로 쉽고 상세하게 알아 보겠습니다!
AI 시대의 새로운 전쟁터: '훈련'에서 '추론'으로
AI 모델을 이야기할 때 우리는 흔히 '훈련(Training)' 과정을 떠올립니다. 방대한 데이터를 학습시켜 똑똑한 AI 모델을 만드는 과정이죠. 하지만 실제 AI가 우리 삶에 가치를 더하는 순간은 바로 '추론(Inference)' 단계입니다.
- 추론이란? 잘 훈련된 AI 모델이 새로운 데이터를 입력받아 실제로 예측, 분류, 생성 등의 작업을 수행하는 과정을 말합니다. 우리가 챗봇에게 질문하고 답변을 받거나, 이미지 생성 AI로 그림을 만들거나, 번역 앱을 사용하는 모든 순간이 바로 추론입니다.
- 왜 추론이 중요해졌나? AI 모델들이 점점 더 커지고 복잡해지면서, 이 모델들을 실제 서비스에서 빠르고 효율적으로 구동하는 추론 단계의 중요성이 커지고 있습니다. AI 서비스가 확산될수록 훈련보다 추론에 훨씬 더 많은 컴퓨팅 자원과 전력이 소모됩니다. (참고문헌 1) 기업 입장에서는 추론 비용과 속도, 에너지 효율성이 AI 서비스의 경쟁력을 좌우하는 핵심 요소가 된 것입니다.
엔비디아 GPU가 AI 훈련 시장을 장악하고 있다면, 이제 AI 기업들은 추론 시장에서의 우위를 점하기 위해 자체적인 솔루션 개발에 열을 올리고 있습니다. 구글의 아이언우드 출시는 바로 이러한 '추론 전쟁' 시대에 대한 구글의 강력한 응답이라고 할 수 있습니다.

베일 벗은 괴물 칩, 아이언우드(Ironwood) 집중 분석
구글 클라우드는 최근(2024년 7월 9일 현지시간) 차세대 텐서 처리 장치(Tensor Processing Unit, TPU)인 아이언우드(Ironwood)를 공식 발표했습니다. TPU는 구글이 머신러닝 워크로드, 특히 자체 개발한 텐서플로우(TensorFlow) 프레임워크에 최적화하여 설계한 맞춤형 ASIC(주문형 반도체)입니다. (참고문헌 2)
아이언우드는 구글의 7세대 TPU이자, AI 추론 성능에 특화되어 설계된 최초의 구글 TPU라는 점에서 특별한 의미를 갖습니다. 주요 특징과 성능은 다음과 같습니다.
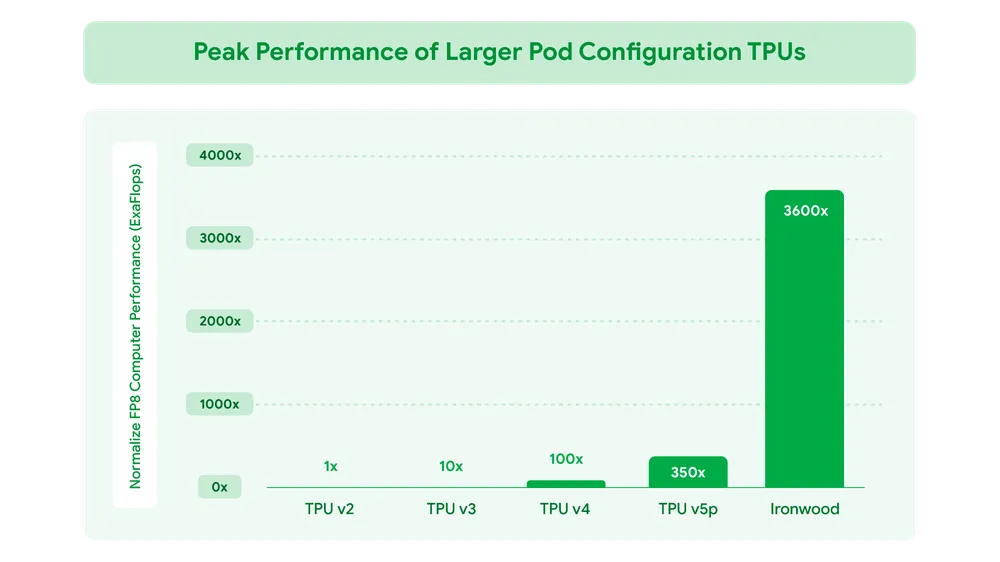
- 압도적인 추론 성능 향상:
- 이전 세대인 6세대 TPU '트릴리움(Trillium)' 대비 AI 추론 속도가 무려 10배 향상되었습니다. 이는 AI 서비스의 응답 속도를 획기적으로 단축시키고, 더 복잡한 모델을 실시간으로 구동할 수 있게 함을 의미합니다.
- 포드(Pod) 구성 시 최대 42.5 엑사플롭스(Exaflops) 연산: 9216개의 아이언우드 칩을 연결한 '포드' 클러스터 구성에서 최대 42.5 엑사플롭스(1초에 10의 18제곱 번 연산)라는 엄청난 연산 능력을 제공합니다. (Exaflops 수치는 특정 정밀도(예: FP8, INT8) 기준일 가능성이 높으며, 추론 연산에 최적화된 성능을 나타냅니다.)
- (참고: 일부 기사에서는 '트릴리움 대비 5배 강력한 컴퓨팅 성능'으로 언급되기도 했는데, 이는 일반적인 컴퓨팅 성능과 '추론 특화 성능' 간의 차이일 수 있습니다. 구글은 '추론 속도 10배'를 공식적으로 강조하고 있습니다.)
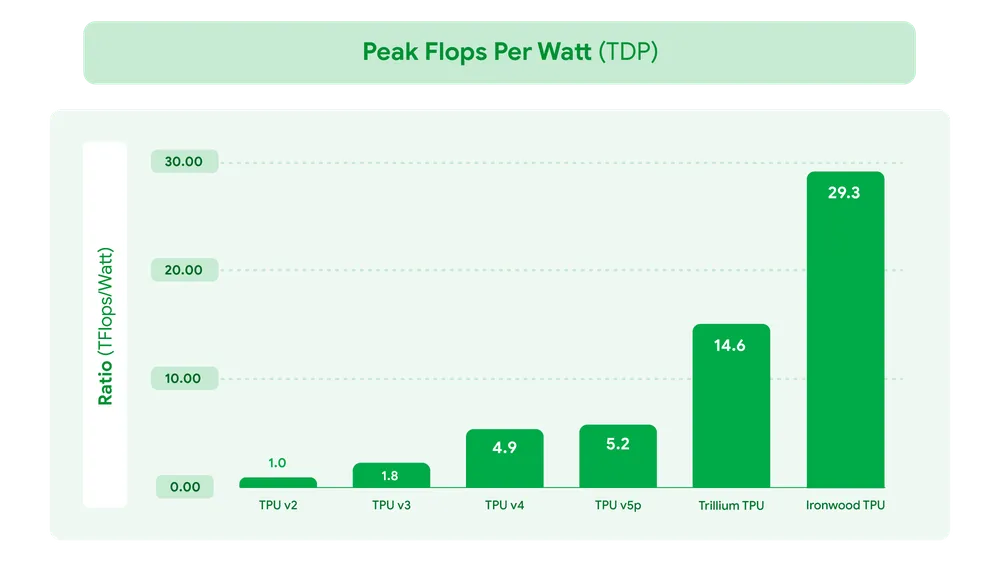
- 향상된 에너지 효율:
- 전력 대비 성능(Performance per Watt)이 트릴리움 대비 2배 향상되었습니다. 이는 대규모 AI 추론 작업을 수행하는 데이터센터의 운영 비용과 탄소 배출량을 줄이는 데 크게 기여합니다. 아민 바흐다트 구글 클라우드 부사장은 "아이언우드는 구글이 개발한 가장 강력하면서도 에너지 효율적인 TPU"라고 강조했습니다. 와트당 29.3 테라플롭(Tflop)의 성능은 2018년 1세대 TPU 대비 약 30배 향상된 수치입니다.
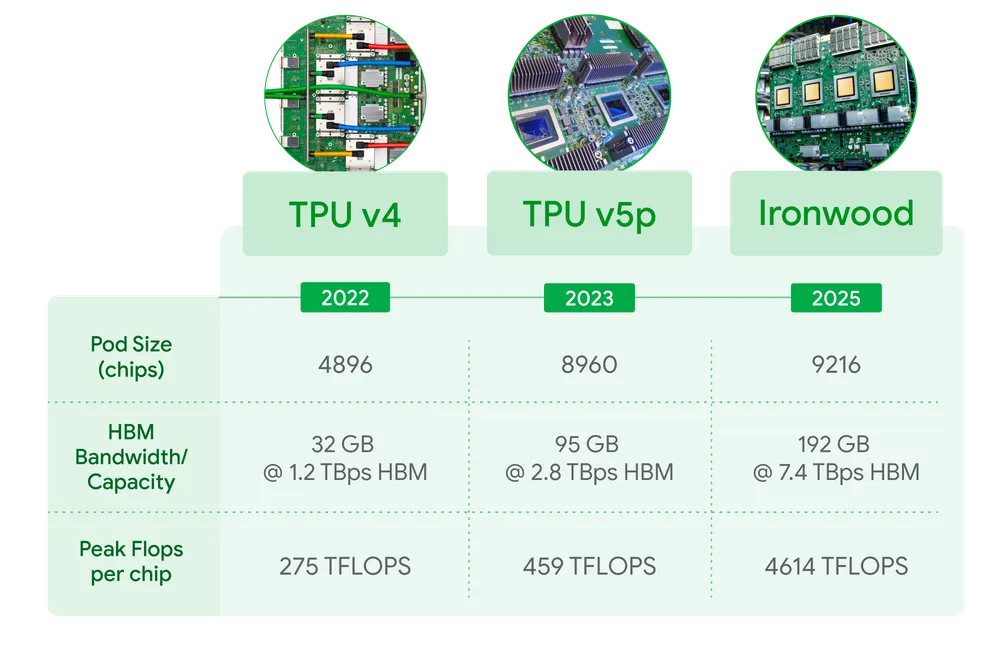
- 대폭 늘어난 메모리 용량 및 대역폭:
- 고대역폭 메모리(HBM) 용량이 이전 세대보다 6배 커졌습니다. 이는 거대 언어 모델(LLM)과 같이 파라미터 수가 매우 큰 모델을 메모리에 더 많이 로드하여 추론 성능을 높이는 데 필수적입니다. (각 칩당 192GB HBM, 7.2 Tbit/s 대역폭 지원 언급)
- 추론 워크로드 최적화 설계:
- 아이언우드는 단순히 연산 능력만 높인 것이 아니라, AI 추론 작업의 특성(낮은 지연 시간 요구, 다양한 모델 크기 처리 등)에 맞춰 아키텍처가 최적화되었습니다. 구체적인 아키텍처 정보는 제한적이지만, INT8/FP8 등 낮은 정밀도 연산 효율 극대화, 메모리 접근 최적화 등이 적용되었을 것으로 추정됩니다. (참고문헌 3)
- 확장성 및 가용성:
- 개별 칩은 수냉식 쿨링 시스템을 적용하여 발열을 관리합니다.
- 올해 말부터 구글 클라우드 고객에게 256개 또는 9216개 칩 구성의 포드(Pod) 형태로 제공될 예정입니다. 이는 소규모 테스트부터 초거대 AI 모델 추론까지 다양한 규모의 요구사항에 대응할 수 있음을 의미합니다.
왜 구글은 자체 칩 'TPU'에 집착할까?
구글이 막대한 비용과 노력을 들여 자체 AI 칩인 TPU를 개발하고 아이언우드까지 선보인 이유는 무엇일까요? 여기에는 몇 가지 중요한 전략적 이유가 있습니다.
- 수직 통합(Vertical Integration)의 힘: 구글은 자체 AI 모델(제미니 등), 소프트웨어 프레임워크(텐서플로우, JAX), 클라우드 플랫폼(Google Cloud), 그리고 이제 하드웨어(TPU)까지 AI 개발 및 서비스의 전 과정을 아우르는 수직 통합 생태계를 구축하고 있습니다. 이는 각 요소가 서로에게 최적화되어 최고의 시너지를 낼 수 있게 합니다. 예를 들어, 제미니 모델은 TPU에서 가장 효율적으로 작동하도록 설계될 수 있으며, 이는 경쟁사 대비 성능 및 비용 우위를 확보하는 강력한 무기가 됩니다.
- 비용 효율성 및 공급망 안정: 엔비디아 GPU에 대한 높은 의존도에서 벗어나 자체 칩을 사용함으로써 AI 서비스 운영 비용을 절감하고, 공급망 변동성 위험을 줄일 수 있습니다. 특히 추론 작업은 지속적으로 대규모로 발생하므로, 추론 비용 절감은 수익성에 직접적인 영향을 미칩니다. 구글은 제미니 플래시 2.0 모델을 TPU 아이언우드에서 실행할 경우, GPT-4o 대비 워크로드당 24배, DeepSeek-R1 대비 5배 높은 추론 성능(비용 대비 효율성 의미 가능성)을 제공할 수 있다고 주장합니다.
- 특화된 성능 요구 충족: 범용 GPU와 달리, TPU는 처음부터 구글의 AI 워크로드(특히 텐서플로우 기반의 대규모 행렬 연산)에 맞춰 설계되었습니다. 아이언우드는 여기서 더 나아가 '추론'이라는 특정 작업에 극도로 최적화된 성능을 제공함으로써, 범용 칩으로는 달성하기 어려운 수준의 효율성을 목표로 합니다.
- 클라우드 경쟁력 강화: 강력하고 비용 효율적인 자체 AI 가속기는 구글 클라우드 플랫폼의 매력을 높여 AWS, 마이크로소프트 애저 등 경쟁사와의 클라우드 전쟁에서 중요한 차별화 요소가 됩니다. 실제로 오픈AI 공동 창립자였던 일리아 수츠케버가 설립한 AI 스타트업 SSI(Safe Superintelligence Inc.)가 주요 컴퓨팅 공급업체로 구글 클라우드를 선택한 것은 이러한 구글의 AI 인프라 경쟁력을 보여주는 사례입니다. (수츠케버는 구글 브레인 출신이기도 합니다.)
아이언우드를 뒷받침하는 구글의 AI 인프라 생태계
아이언우드 칩 자체의 성능도 중요하지만, 이 칩의 능력을 최대한 끌어내기 위해서는 주변 인프라와의 통합이 필수적입니다. 구글은 아이언우드와 함께 다음과 같은 기술들을 통해 시너지를 창출합니다.
- AI 하이퍼컴퓨터 (AI Hypercomputer): 구글 클라우드가 제공하는 통합적인 AI 인프라 아키텍처입니다. 단순히 하드웨어(TPU, GPU, CPU)뿐만 아니라 고성능 네트워킹, 스토리지, 그리고 최적화된 소프트웨어 스택까지 포함하여 AI 워크로드를 위한 최상의 환경을 제공합니다.
- 패스웨이즈 (Pathways): 구글 딥마인드가 개발한 차세대 AI 아키텍처이자 머신러닝 런타임입니다. 패스웨이즈는 여러 개의 아이언우드 포드를 마치 하나의 거대한 슈퍼컴퓨터처럼 연결하고 관리할 수 있게 해줍니다. 수만, 수십만 개의 칩을 동적으로 활용하여 AI 추론의 각 단계를 분산 처리하고 확장함으로써, 응답 지연 시간을 최소화하고 데이터 처리량을 극대화합니다. 이는 초거대 AI 모델이나 복잡한 AI 에이전트 워크로드를 효율적으로 처리하는 데 핵심적인 역할을 합니다.
- 구글 쿠버네티스 엔진 (GKE) 추론 최적화: 컨테이너 기반 애플리케이션 배포 및 관리를 위한 GKE에도 AI 추론 워크로드를 위한 기능들이 추가되었습니다.
- GKE 추론 게이트웨이: 모델의 특성을 인지하여 로드 밸런싱과 확장을 지능적으로 수행함으로써 추론 비용을 최대 30%, 지연 시간을 최대 60%까지 절감할 수 있다고 합니다.
- GKE 추론 권장사항 (프리뷰): 사용자가 목표하는 AI 모델과 성능 수준에 맞춰 최적의 쿠버네티스 및 인프라 구성을 추천해주는 기능입니다.
이처럼 구글은 아이언우드라는 강력한 엔진과 함께, 이를 뒷받침하는 정교한 시스템 소프트웨어 및 클라우드 인프라를 통해 AI 추론 시장에서의 리더십을 공고히 하려 하고 있습니다.
아이언우드가 가져올 미래: 기대와 전망
구글의 아이언우드 출시는 AI 산업 전반에 걸쳐 적지 않은 파급 효과를 가져올 것으로 예상됩니다.
- AI 서비스의 가속화 및 비용 절감: 더 빠르고 저렴한 추론 인프라는 더 많은 기업들이 AI 기술을 도입하고 혁신적인 서비스를 개발하도록 촉진할 것입니다. 특히 실시간 응답이 중요한 대화형 AI, AI 에이전트, 추천 시스템 등의 성능 향상이 기대됩니다.
- 거대 AI 모델의 보편화: 아이언우드와 같은 고성능 추론 칩은 파라미터 수가 조 단위를 넘어서는 초거대 AI 모델의 운영 부담을 줄여, 이러한 모델들의 활용도를 높이는 데 기여할 것입니다.
- AI 칩 경쟁 심화: 구글의 성공은 AWS(Inferentia, Trainium), 마이크로소프트(Maia) 등 다른 클라우드 기업들의 자체 AI 칩 개발 경쟁을 더욱 부추길 것이며, 엔비디아 GPU의 아성에 도전하는 움직임이 가속화될 것입니다.
- 새로운 AI 애플리케이션 등장: 향상된 추론 능력은 이전에는 불가능했던 새로운 유형의 AI 애플리케이션 등장을 가능하게 할 수 있습니다. 예를 들어, 더욱 정교하고 자율적인 판단 능력을 갖춘 AI 에이전트의 확산이 빨라질 수 있습니다.
물론, 아이언우드의 실제 성능과 효율성은 구글 클라우드 환경 밖에서 독립적으로 검증되기 어렵다는 점, 특정 워크로드(텐서플로우 등)에 대한 최적화가 다른 프레임워크에서는 불리하게 작용할 수 있다는 점 등은 고려해야 할 부분입니다.
추론 시대를 정조준한 구글의 승부수
구글의 7세대 TPU '아이언우드'는 단순한 하드웨어 업그레이드를 넘어, AI 산업의 무게 중심이 '추론'으로 이동하는 시대적 변화에 발맞춘 구글의 전략적 승부수입니다. 압도적인 추론 성능 향상과 에너지 효율 개선, 그리고 자체 AI 모델 및 클라우드 인프라와의 긴밀한 통합은 구글에게 강력한 경쟁 우위를 제공할 것입니다.
AI 기술이 우리 삶 곳곳에 스며드는 속도가 빨라질수록, 그 기반이 되는 인프라의 중요성은 더욱 커질 수밖에 없습니다. 아이언우드는 AI 추론 시대를 이끌어갈 핵심 동력 중 하나로 자리매김하며, 앞으로 우리가 경험하게 될 AI 서비스의 품질과 속도를 결정짓는 중요한 역할을 할 것으로 기대됩니다. 구글의 'AI 심장'이 얼마나 더 강력하게 박동할지, 앞으로의 행보를 주목해야 할 이유입니다.
참고자료 (References):
- Reuther, A., Michaleas, P., Jones, M., Gadepally, V., Samsi, S., & Kepner, J. (2020). Survey of machine learning accelerators. In 2020 IEEE High Performance Extreme Computing Conference (HPEC) (pp. 1-12). IEEE. (AI 훈련과 추론의 컴퓨팅 요구사항 차이 및 가속기 필요성 논의)
- Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., ... & Yoon, D. H. (2017, June). In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th annual international symposium on computer architecture (pp. 1-12). (구글 TPU v1의 아키텍처 및 성능 분석)
- Kim, J., Kung, H. T., & Lee, K. W. (2021). Challenges and opportunities in ai inference acceleration. IEEE Micro, 41(4), 18-25. (AI 추론 가속의 기술적 과제 및 동향)
- Google Cloud Blog. (Relevant posts regarding TPU announcements, AI Hypercomputer, Pathways - Specific post URLs needed if available, otherwise cite the blog generally)
- Vahdat, Amin (Google Cloud VP). (Statements from press briefings or official announcements regarding Ironwood performance and strategy - Requires citation of the specific event or press release)
- Announcing Ironwood: Our next-generation TPUs optimized for AI inference
(https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/) - Google Cloud launches Ironwood, its next-gen TPUs optimized for AI inference
(https://techcrunch.com/2025/04/09/google-unveils-ironwood-a-new-ai-accelerator-chip/)